This document describes the current stable version of Celery (3.1). For development docs, go here.
Calling Tasks¶
Basics¶
This document describes Celery’s uniform “Calling API” used by task instances and the canvas.
The API defines a standard set of execution options, as well as three methods:
apply_async(args[, kwargs[, …]])Sends a task message.
delay(*args, **kwargs)Shortcut to send a task message, but does not support execution options.
calling (
__call__)Applying an object supporting the calling API (e.g.
add(2, 2)) means that the task will be executed in the current process, and not by a worker (a message will not be sent).
Quick Cheat Sheet
T.delay(arg, kwarg=value)- always a shortcut to
.apply_async.
T.apply_async((arg, ), {'kwarg': value})T.apply_async(countdown=10)- executes 10 seconds from now.
T.apply_async(eta=now + timedelta(seconds=10))- executes 10 seconds from now, specifed using
eta
T.apply_async(countdown=60, expires=120)- executes in one minute from now, but expires after 2 minutes.
T.apply_async(expires=now + timedelta(days=2))- expires in 2 days, set using
datetime.
Example¶
The delay() method is convenient as it looks like calling a regular
function:
task.delay(arg1, arg2, kwarg1='x', kwarg2='y')
Using apply_async() instead you have to write:
task.apply_async(args=[arg1, arg2], kwargs={'kwarg1': 'x', 'kwarg2': 'y'})
So delay is clearly convenient, but if you want to set additional execution
options you have to use apply_async.
The rest of this document will go into the task execution options in detail. All examples use a task called add, returning the sum of two arguments:
@app.task
def add(x, y):
return x + y
There’s another way…
You will learn more about this later while reading about the Canvas, but subtask‘s are objects used to pass around
the signature of a task invocation, (for example to send it over the
network), and they also support the Calling API:
task.s(arg1, arg2, kwarg1='x', kwargs2='y').apply_async()
Linking (callbacks/errbacks)¶
Celery supports linking tasks together so that one task follows another. The callback task will be applied with the result of the parent task as a partial argument:
add.apply_async((2, 2), link=add.s(16))
Here the result of the first task (4) will be sent to a new
task that adds 16 to the previous result, forming the expression
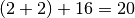
You can also cause a callback to be applied if task raises an exception (errback), but this behaves differently from a regular callback in that it will be passed the id of the parent task, not the result. This is because it may not always be possible to serialize the exception raised, and so this way the error callback requires a result backend to be enabled, and the task must retrieve the result of the task instead.
This is an example error callback:
@app.task(bind=True)
def error_handler(self, uuid):
result = self.app.AsyncResult(uuid)
print('Task {0} raised exception: {1!r}\n{2!r}'.format(
uuid, result.result, result.traceback))
it can be added to the task using the link_error execution
option:
add.apply_async((2, 2), link_error=error_handler.s())
In addition, both the link and link_error options can be expressed
as a list:
add.apply_async((2, 2), link=[add.s(16), other_task.s()])
The callbacks/errbacks will then be called in order, and all callbacks will be called with the return value of the parent task as a partial argument.
ETA and countdown¶
The ETA (estimated time of arrival) lets you set a specific date and time that is the earliest time at which your task will be executed. countdown is a shortcut to set eta by seconds into the future.
>>> result = add.apply_async((2, 2), countdown=3)
>>> result.get() # this takes at least 3 seconds to return
20
The task is guaranteed to be executed at some time after the specified date and time, but not necessarily at that exact time. Possible reasons for broken deadlines may include many items waiting in the queue, or heavy network latency. To make sure your tasks are executed in a timely manner you should monitor the queue for congestion. Use Munin, or similar tools, to receive alerts, so appropriate action can be taken to ease the workload. See Munin.
While countdown is an integer, eta must be a datetime
object, specifying an exact date and time (including millisecond precision,
and timezone information):
>>> from datetime import datetime, timedelta
>>> tomorrow = datetime.utcnow() + timedelta(days=1)
>>> add.apply_async((2, 2), eta=tomorrow)
Expiration¶
The expires argument defines an optional expiry time,
either as seconds after task publish, or a specific date and time using
datetime:
>>> # Task expires after one minute from now.
>>> add.apply_async((10, 10), expires=60)
>>> # Also supports datetime
>>> from datetime import datetime, timedelta
>>> add.apply_async((10, 10), kwargs,
... expires=datetime.now() + timedelta(days=1)
When a worker receives an expired task it will mark
the task as REVOKED (TaskRevokedError).
Message Sending Retry¶
Celery will automatically retry sending messages in the event of connection failure, and retry behavior can be configured – like how often to retry, or a maximum number of retries – or disabled all together.
To disable retry you can set the retry execution option to False:
add.apply_async((2, 2), retry=False)
Related Settings
Retry Policy¶
A retry policy is a mapping that controls how retries behave, and can contain the following keys:
max_retries
Maximum number of retries before giving up, in this case the exception that caused the retry to fail will be raised.
A value of 0 or
Nonemeans it will retry forever.The default is to retry 3 times.
interval_start
Defines the number of seconds (float or integer) to wait between retries. Default is 0, which means the first retry will be instantaneous.
interval_step
On each consecutive retry this number will be added to the retry delay (float or integer). Default is 0.2.
interval_max
Maximum number of seconds (float or integer) to wait between retries. Default is 0.2.
For example, the default policy correlates to:
add.apply_async((2, 2), retry=True, retry_policy={
'max_retries': 3,
'interval_start': 0,
'interval_step': 0.2,
'interval_max': 0.2,
})
the maximum time spent retrying will be 0.4 seconds. It is set relatively short by default because a connection failure could lead to a retry pile effect if the broker connection is down: e.g. many web server processes waiting to retry blocking other incoming requests.
Serializers¶
Data transferred between clients and workers needs to be serialized,
so every message in Celery has a content_type header that
describes the serialization method used to encode it.
The default serializer is pickle, but you can
change this using the CELERY_TASK_SERIALIZER setting,
or for each individual task, or even per message.
There’s built-in support for pickle, JSON, YAML
and msgpack, and you can also add your own custom serializers by registering
them into the Kombu serializer registry (see ref:kombu:guide-serialization).
Each option has its advantages and disadvantages.
- json – JSON is supported in many programming languages, is now
a standard part of Python (since 2.6), and is fairly fast to decode using the modern Python libraries such as
cjsonorsimplejson.The primary disadvantage to JSON is that it limits you to the following data types: strings, Unicode, floats, boolean, dictionaries, and lists. Decimals and dates are notably missing.
Also, binary data will be transferred using Base64 encoding, which will cause the transferred data to be around 34% larger than an encoding which supports native binary types.
However, if your data fits inside the above constraints and you need cross-language support, the default setting of JSON is probably your best choice.
See http://json.org for more information.
- pickle – If you have no desire to support any language other than
Python, then using the pickle encoding will gain you the support of all built-in Python data types (except class instances), smaller messages when sending binary files, and a slight speedup over JSON processing.
See http://docs.python.org/library/pickle.html for more information.
- yaml – YAML has many of the same characteristics as json,
except that it natively supports more data types (including dates, recursive references, etc.)
However, the Python libraries for YAML are a good bit slower than the libraries for JSON.
If you need a more expressive set of data types and need to maintain cross-language compatibility, then YAML may be a better fit than the above.
See http://yaml.org/ for more information.
- msgpack – msgpack is a binary serialization format that is closer to JSON
in features. It is very young however, and support should be considered experimental at this point.
See http://msgpack.org/ for more information.
The encoding used is available as a message header, so the worker knows how to deserialize any task. If you use a custom serializer, this serializer must be available for the worker.
The following order is used to decide which serializer to use when sending a task:
- The serializer execution option.
- The
Task.serializerattribute- The
CELERY_TASK_SERIALIZERsetting.
Example setting a custom serializer for a single task invocation:
>>> add.apply_async((10, 10), serializer='json')
Compression¶
Celery can compress the messages using either gzip, or bzip2.
You can also create your own compression schemes and register
them in the kombu compression registry.
The following order is used to decide which compression scheme to use when sending a task:
- The compression execution option.
- The
Task.compressionattribute.- The
CELERY_MESSAGE_COMPRESSIONattribute.
Example specifying the compression used when calling a task:
>>> add.apply_async((2, 2), compression='zlib')
Connections¶
You can handle the connection manually by creating a publisher:
results = []
with add.app.pool.acquire(block=True) as connection:
with add.get_publisher(connection) as publisher:
try:
for args in numbers:
res = add.apply_async((2, 2), publisher=publisher)
results.append(res)
print([res.get() for res in results])
Though this particular example is much better expressed as a group:
>>> from celery import group
>>> numbers = [(2, 2), (4, 4), (8, 8), (16, 16)]
>>> res = group(add.s(i) for i in numbers).apply_async()
>>> res.get()
[4, 8, 16, 32]
Routing options¶
Celery can route tasks to different queues.
Simple routing (name <-> name) is accomplished using the queue option:
add.apply_async(queue='priority.high')
You can then assign workers to the priority.high queue by using
the workers -Q argument:
$ celery -A proj worker -l info -Q celery,priority.high
See also
Hard-coding queue names in code is not recommended, the best practice
is to use configuration routers (CELERY_ROUTES).
To find out more about routing, please see Routing Tasks.
Advanced Options¶
These options are for advanced users who want to take use of AMQP’s full routing capabilities. Interested parties may read the routing guide.
exchange
Name of exchange (or a
kombu.entity.Exchange) to send the message to.routing_key
Routing key used to determine.
priority
A number between 0 and 9, where 0 is the highest priority.
Supported by: redis, beanstalk
