This document describes the current stable version of Celery (5.6). For development docs, go here.
Change history for Celery 2.0¶
2.0.3¶
- release-date:
2010-08-27 12:00 p.m. CEST
- release-by:
Ask Solem
Fixes¶
Worker: Properly handle connection errors happening while closing consumers.
Worker: Events are now buffered if the connection is down, then sent when the connection is re-established.
No longer depends on the https://pypi.org/project/mailer/ package.
This package had a name space collision with django-mailer, so its functionality was replaced.
Redis result backend: Documentation typos: Redis doesn’t have database names, but database numbers. The default database is now 0.
inspect: registered_tasks was requesting an invalid command because of a typo.See issue #170.
CELERY_ROUTES: Values defined in the route should now have precedence over values defined inCELERY_QUEUESwhen merging the two.With the follow settings:
CELERY_QUEUES = {'cpubound': {'exchange': 'cpubound', 'routing_key': 'cpubound'}} CELERY_ROUTES = {'tasks.add': {'queue': 'cpubound', 'routing_key': 'tasks.add', 'serializer': 'json'}}
The final routing options for tasks.add will become:
{'exchange': 'cpubound', 'routing_key': 'tasks.add', 'serializer': 'json'}
This wasn’t the case before: the values in
CELERY_QUEUESwould take precedence.Worker crashed if the value of
CELERY_TASK_ERROR_WHITELISTwas not an iterableapply(): Make sure kwargs[‘task_id’] is always set.AsyncResult.traceback: Now returns
None, instead of raisingKeyErrorif traceback is missing.inspect: Replies didn’t work correctly if no destination was specified.Can now store result/meta-data for custom states.
Worker: A warning is now emitted if the sending of task error emails fails.
celeryev: Curses monitor no longer crashes if the terminal window is resized.See issue #160.
Worker: On macOS it isn’t possible to run os.exec* in a process that’s threaded.
This breaks the SIGHUP restart handler, and is now disabled on macOS, emitting a warning instead.
See issue #152.
celery.execute.trace: Properly handle raise(str), which is still allowed in Python 2.4.See issue #175.
Using urllib2 in a periodic task on macOS crashed because of the proxy auto detection used in macOS.
This is now fixed by using a workaround. See issue #143.
Debian init-scripts: Commands shouldn’t run in a sub shell
See issue #163.
Debian init-scripts: Use the absolute path of
celerydprogram to allow statSee issue #162.
Documentation¶
getting-started/broker-installation: Fixed typo
set_permissions “” -> set_permissions “.*”.
Tasks User Guide: Added section on database transactions.
See issue #169.
Routing User Guide: Fixed typo “feed”: -> {“queue”: “feeds”}.
See issue #169.
Documented the default values for the
CELERYD_CONCURRENCYandCELERYD_PREFETCH_MULTIPLIERsettings.Tasks User Guide: Fixed typos in the subtask example
celery.signals: Documented worker_process_init.
Daemonization cookbook: Need to export DJANGO_SETTINGS_MODULE in /etc/default/celeryd.
Added some more FAQs from stack overflow
Daemonization cookbook: Fixed typo CELERYD_LOGFILE/CELERYD_PIDFILE
to CELERYD_LOG_FILE / CELERYD_PID_FILE
Also added troubleshooting section for the init-scripts.
2.0.2¶
- release-date:
2010-07-22 11:31 a.m. CEST
- release-by:
Ask Solem
Routes: When using the dict route syntax, the exchange for a task could disappear making the task unroutable.
See issue #158.
Test suite now passing on Python 2.4
No longer have to type PYTHONPATH=. to use
celeryconfigin the current directory.This is accomplished by the default loader ensuring that the current directory is in sys.path when loading the config module. sys.path is reset to its original state after loading.
Adding the current working directory to sys.path without the user knowing may be a security issue, as this means someone can drop a Python module in the users directory that executes arbitrary commands. This was the original reason not to do this, but if done only when loading the config module, this means that the behavior will only apply to the modules imported in the config module, which I think is a good compromise (certainly better than just explicitly setting PYTHONPATH=. anyway)
Experimental Cassandra backend added.
Worker: SIGHUP handler accidentally propagated to worker pool processes.
In combination with GitHub SHA@7a7c44e39344789f11b5346e9cc8340f5fe4846c this would make each child process start a new worker instance when the terminal window was closed :/
Worker: Don’t install SIGHUP handler if running from a terminal.
This fixes the problem where the worker is launched in the background when closing the terminal.
Worker: Now joins threads at shutdown.
See issue #152.
Test tear down: Don’t use atexit but nose’s teardown() functionality instead.
See issue #154.
Debian worker init-script: Stop now works correctly.
Task logger: warn method added (synonym for warning)
Can now define a white list of errors to send error emails for.
Example:
CELERY_TASK_ERROR_WHITELIST = ('myapp.MalformedInputError',)
See issue #153.
Worker: Now handles overflow exceptions in time.mktime while parsing the ETA field.
LoggerWrapper: Try to detect loggers logging back to stderr/stdout making an infinite loop.
Added
celery.task.control.inspect: Inspects a running worker.Examples:
# Inspect a single worker >>> i = inspect('myworker.example.com') # Inspect several workers >>> i = inspect(['myworker.example.com', 'myworker2.example.com']) # Inspect all workers consuming on this vhost. >>> i = inspect() ### Methods # Get currently executing tasks >>> i.active() # Get currently reserved tasks >>> i.reserved() # Get the current ETA schedule >>> i.scheduled() # Worker statistics and info >>> i.stats() # List of currently revoked tasks >>> i.revoked() # List of registered tasks >>> i.registered_tasks()
Remote control commands dump_active/dump_reserved/dump_schedule now replies with detailed task requests.
Containing the original arguments and fields of the task requested.
In addition the remote control command set_loglevel has been added, this only changes the log level for the main process.
Worker control command execution now catches errors and returns their string representation in the reply.
Functional test suite added
celery.tests.functional.casecontains utilities to start and stop an embedded worker process, for use in functional testing.
2.0.1¶
- release-date:
2010-07-09 03:02 p.m. CEST
- release-by:
Ask Solem
multiprocessing.pool: Now handles encoding errors, so that pickling errors doesn’t crash the worker processes.
The remote control command replies wasn’t working with RabbitMQ 1.8.0’s stricter equivalence checks.
If you’ve already hit this problem you may have to delete the declaration:
$ camqadm exchange.delete celerycrq
or:
$ python manage.py camqadm exchange.delete celerycrq
A bug sneaked in the ETA scheduler that made it only able to execute one task per second(!)
The scheduler sleeps between iterations so it doesn’t consume too much CPU. It keeps a list of the scheduled items sorted by time, at each iteration it sleeps for the remaining time of the item with the nearest deadline. If there are no ETA tasks it will sleep for a minimum amount of time, one second by default.
A bug sneaked in here, making it sleep for one second for every task that was scheduled. This has been fixed, so now it should move tasks like hot knife through butter.
In addition a new setting has been added to control the minimum sleep interval;
CELERYD_ETA_SCHEDULER_PRECISION. A good value for this would be a float between 0 and 1, depending on the needed precision. A value of 0.8 means that when the ETA of a task is met, it will take at most 0.8 seconds for the task to be moved to the ready queue.Pool: Supervisor didn’t release the semaphore.
This would lead to a deadlock if all workers terminated prematurely.
Added Python version trove classifiers: 2.4, 2.5, 2.6 and 2.7
Tests now passing on Python 2.7.
Task.__reduce__: Tasks created using the task decorator can now be pickled.
setup.py: https://pypi.org/project/nose/ added to tests_require.Pickle should now work with SQLAlchemy 0.5.x
New homepage design by Jan Henrik Helmers: http://celeryproject.org
New Sphinx theme by Armin Ronacher: https://docs.celeryq.dev/
Fixed “pending_xref” errors shown in the HTML rendering of the documentation. Apparently this was caused by new changes in Sphinx 1.0b2.
Router classes in
CELERY_ROUTESare now imported lazily.Importing a router class in a module that also loads the Celery environment would cause a circular dependency. This is solved by importing it when needed after the environment is set up.
CELERY_ROUTESwas broken if set to a single dict.This example in the docs should now work again:
CELERY_ROUTES = {'feed.tasks.import_feed': 'feeds'}
CREATE_MISSING_QUEUES wasn’t honored by apply_async.
New remote control command: stats
Dumps information about the worker, like pool process ids, and total number of tasks executed by type.
Example reply:
[{'worker.local': 'total': {'tasks.sleeptask': 6}, 'pool': {'timeouts': [None, None], 'processes': [60376, 60377], 'max-concurrency': 2, 'max-tasks-per-child': None, 'put-guarded-by-semaphore': True}}]
New remote control command: dump_active
Gives a list of tasks currently being executed by the worker. By default arguments are passed through repr in case there are arguments that’s not JSON encodable. If you know the arguments are JSON safe, you can pass the argument safe=True.
Example reply:
>>> broadcast('dump_active', arguments={'safe': False}, reply=True) [{'worker.local': [ {'args': '(1,)', 'time_start': 1278580542.6300001, 'name': 'tasks.sleeptask', 'delivery_info': { 'consumer_tag': '30', 'routing_key': 'celery', 'exchange': 'celery'}, 'hostname': 'casper.local', 'acknowledged': True, 'kwargs': '{}', 'id': '802e93e9-e470-47ed-b913-06de8510aca2', } ]}]
Added experimental support for persistent revokes.
Use the -S|–statedb argument to the worker to enable it:
$ celeryd --statedb=/var/run/celeryd
This will use the file: /var/run/celeryd.db, as the shelve module automatically adds the .db suffix.
2.0.0¶
- release-date:
2010-07-02 02:30 p.m. CEST
- release-by:
Ask Solem
Foreword¶
Celery 2.0 contains backward incompatible changes, the most important being that the Django dependency has been removed so Celery no longer supports Django out of the box, but instead as an add-on package called https://pypi.org/project/django-celery/.
We’re very sorry for breaking backwards compatibility, but there’s also many new and exciting features to make up for the time you lose upgrading, so be sure to read the News section.
Quite a lot of potential users have been upset about the Django dependency, so maybe this is a chance to get wider adoption by the Python community as well.
Big thanks to all contributors, testers and users!
Upgrading for Django-users¶
Django integration has been moved to a separate package: https://pypi.org/project/django-celery/.
To upgrade you need to install the https://pypi.org/project/django-celery/ module and change:
INSTALLED_APPS = 'celery'
to:
INSTALLED_APPS = 'djcelery'
If you use mod_wsgi you need to add the following line to your .wsgi file:
import os os.environ['CELERY_LOADER'] = 'django'
The following modules has been moved to https://pypi.org/project/django-celery/:
Module name
Replace with
celery.models
djcelery.models
celery.managers
djcelery.managers
celery.views
djcelery.views
celery.urls
djcelery.urls
celery.management
djcelery.management
celery.loaders.djangoapp
djcelery.loaders
celery.backends.database
djcelery.backends.database
celery.backends.cache
djcelery.backends.cache
Importing djcelery will automatically setup Celery to use Django loader.
loader. It does this by setting the CELERY_LOADER environment variable to
“django” (it won’t change it if a loader is already set).
When the Django loader is used, the “database” and “cache” result backend
aliases will point to the djcelery backends instead of the built-in backends,
and configuration will be read from the Django settings.
Upgrading for others¶
Database result backend¶
The database result backend is now using SQLAlchemy instead of the Django ORM, see Supported Databases for a table of supported databases.
The DATABASE_* settings has been replaced by a single setting:
CELERY_RESULT_DBURI. The value here should be an
SQLAlchemy Connection String, some examples include:
# sqlite (filename)
CELERY_RESULT_DBURI = 'sqlite:///celerydb.sqlite'
# mysql
CELERY_RESULT_DBURI = 'mysql://scott:tiger@localhost/foo'
# postgresql
CELERY_RESULT_DBURI = 'postgresql://scott:tiger@localhost/mydatabase'
# oracle
CELERY_RESULT_DBURI = 'oracle://scott:tiger@127.0.0.1:1521/sidname'
See SQLAlchemy Connection Strings for more information about connection strings.
To specify additional SQLAlchemy database engine options you can use
the CELERY_RESULT_ENGINE_OPTIONS setting:
# echo enables verbose logging from SQLAlchemy. CELERY_RESULT_ENGINE_OPTIONS = {'echo': True}
Cache result backend¶
The cache result backend is no longer using the Django cache framework, but it supports mostly the same configuration syntax:
CELERY_CACHE_BACKEND = 'memcached://A.example.com:11211;B.example.com'
To use the cache backend you must either have the https://pypi.org/project/pylibmc/ or https://pypi.org/project/python-memcached/ library installed, of which the former is regarded as the best choice.
The support backend types are memcached:// and memory://, we haven’t felt the need to support any of the other backends provided by Django.
Backward incompatible changes¶
Default (python) loader now prints warning on missing celeryconfig.py instead of raising
ImportError.The worker raises
ImproperlyConfiguredif the configuration isn’t set up. This makes it possible to use –help etc., without having a working configuration.Also this makes it possible to use the client side of Celery without being configured:
>>> from carrot.connection import BrokerConnection >>> conn = BrokerConnection('localhost', 'guest', 'guest', '/') >>> from celery.execute import send_task >>> r = send_task('celery.ping', args=(), kwargs={}, connection=conn) >>> from celery.backends.amqp import AMQPBackend >>> r.backend = AMQPBackend(connection=conn) >>> r.get() 'pong'
The following deprecated settings has been removed (as scheduled by the Celery Deprecation Time-line):
Setting name
Replace with
CELERY_AMQP_CONSUMER_QUEUES
CELERY_QUEUES
CELERY_AMQP_EXCHANGE
CELERY_DEFAULT_EXCHANGE
CELERY_AMQP_EXCHANGE_TYPE
CELERY_DEFAULT_EXCHANGE_TYPE
CELERY_AMQP_CONSUMER_ROUTING_KEY
CELERY_QUEUES
CELERY_AMQP_PUBLISHER_ROUTING_KEY
CELERY_DEFAULT_ROUTING_KEY
The celery.task.rest module has been removed, use celery.task.http instead (as scheduled by the Celery Deprecation Time-line).
It’s no longer allowed to skip the class name in loader names. (as scheduled by the Celery Deprecation Time-line):
Assuming the implicit Loader class name is no longer supported, for example, if you use:
CELERY_LOADER = 'myapp.loaders'
You need to include the loader class name, like this:
CELERY_LOADER = 'myapp.loaders.Loader'
CELERY_TASK_RESULT_EXPIRESnow defaults to 1 day.Previous default setting was to expire in 5 days.
AMQP backend: Don’t use different values for auto_delete.
This bug became visible with RabbitMQ 1.8.0, which no longer allows conflicting declarations for the auto_delete and durable settings.
If you’ve already used Celery with this backend chances are you have to delete the previous declaration:
$ camqadm exchange.delete celeryresults
Now uses pickle instead of cPickle on Python versions <= 2.5
cPickle is broken in Python <= 2.5.
It unsafely and incorrectly uses relative instead of absolute imports, so for example:
exceptions.KeyError
becomes:
celery.exceptions.KeyError
Your best choice is to upgrade to Python 2.6, as while the pure pickle version has worse performance, it is the only safe option for older Python versions.
News¶
celeryev: Curses Celery Monitor and Event Viewer.
This is a simple monitor allowing you to see what tasks are executing in real-time and investigate tracebacks and results of ready tasks. It also enables you to set new rate limits and revoke tasks.
Screenshot:
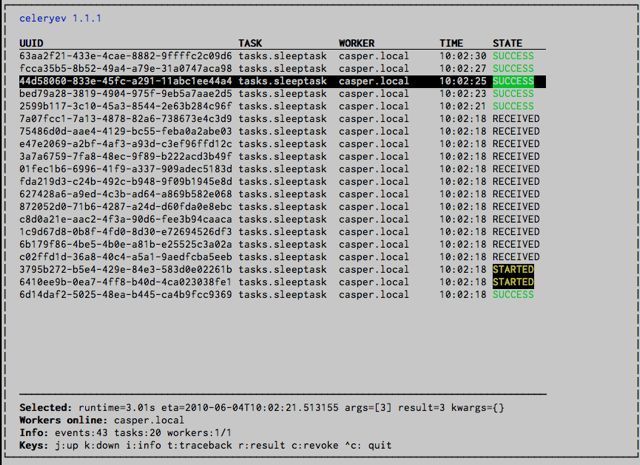
If you run celeryev with the -d switch it will act as an event dumper, simply dumping the events it receives to standard out:
$ celeryev -d -> celeryev: starting capture... casper.local [2010-06-04 10:42:07.020000] heartbeat casper.local [2010-06-04 10:42:14.750000] task received: tasks.add(61a68756-27f4-4879-b816-3cf815672b0e) args=[2, 2] kwargs={} eta=2010-06-04T10:42:16.669290, retries=0 casper.local [2010-06-04 10:42:17.230000] task started tasks.add(61a68756-27f4-4879-b816-3cf815672b0e) args=[2, 2] kwargs={} casper.local [2010-06-04 10:42:17.960000] task succeeded: tasks.add(61a68756-27f4-4879-b816-3cf815672b0e) args=[2, 2] kwargs={} result=4, runtime=0.782663106918 The fields here are, in order: *sender hostname*, *timestamp*, *event type* and *additional event fields*.
AMQP result backend: Now supports .ready(), .successful(), .result, .status, and even responds to changes in task state
New user guides:
Worker: Standard out/error is now being redirected to the log file.
https://pypi.org/project/billiard/ has been moved back to the Celery repository.
Module name
celery equivalent
billiard.pool
celery.concurrency.processes.pool
billiard.serialization
celery.serialization
billiard.utils.functional
celery.utils.functional
The https://pypi.org/project/billiard/ distribution may be maintained, depending on interest.
now depends on https://pypi.org/project/carrot/ >= 0.10.5
now depends on https://pypi.org/project/pyparsing/
Worker: Added –purge as an alias to –discard.
Worker: Control-c (SIGINT) once does warm shutdown, hitting Control-c twice forces termination.
Added support for using complex Crontab-expressions in periodic tasks. For example, you can now use:
>>> crontab(minute='*/15')
or even:
>>> crontab(minute='*/30', hour='8-17,1-2', day_of_week='thu-fri')
See Periodic Tasks.
Worker: Now waits for available pool processes before applying new tasks to the pool.
This means it doesn’t have to wait for dozens of tasks to finish at shutdown because it has applied prefetched tasks without having any pool processes available to immediately accept them.
See issue #122.
New built-in way to do task callbacks using
subtask.See Canvas: Designing Work-flows for more information.
TaskSets can now contain several types of tasks.
TaskSethas been refactored to use a new syntax, please see Canvas: Designing Work-flows for more information.The previous syntax is still supported, but will be deprecated in version 1.4.
TaskSet failed() result was incorrect.
See issue #132.
Now creates different loggers per task class.
See issue #129.
Missing queue definitions are now created automatically.
You can disable this using the
CELERY_CREATE_MISSING_QUEUESsetting.The missing queues are created with the following options:
CELERY_QUEUES[name] = {'exchange': name, 'exchange_type': 'direct', 'routing_key': 'name}
This feature is added for easily setting up routing using the -Q option to the worker:
$ celeryd -Q video, image
See the new routing section of the User Guide for more information: Routing Tasks.
New Task option: Task.queue
If set, message options will be taken from the corresponding entry in
CELERY_QUEUES. exchange, exchange_type and routing_key will be ignoredAdded support for task soft and hard time limits.
New settings added:
CELERYD_TASK_TIME_LIMITHard time limit. The worker processing the task will be killed and replaced with a new one when this is exceeded.
CELERYD_TASK_SOFT_TIME_LIMITSoft time limit. The
SoftTimeLimitExceededexception will be raised when this is exceeded. The task can catch this to, for example, clean up before the hard time limit comes.
New command-line arguments to
celerydadded: –time-limit and –soft-time-limit.What’s left?
This won’t work on platforms not supporting signals (and specifically the SIGUSR1 signal) yet. So an alternative the ability to disable the feature all together on nonconforming platforms must be implemented.
Also when the hard time limit is exceeded, the task result should be a TimeLimitExceeded exception.
Test suite is now passing without a running broker, using the carrot in-memory backend.
Log output is now available in colors.
Log level
Color
DEBUG
Blue
WARNING
Yellow
CRITICAL
Magenta
ERROR
Red
This is only enabled when the log output is a tty. You can explicitly enable/disable this feature using the
CELERYD_LOG_COLORsetting.Added support for task router classes (like the django multi-db routers)
New setting:
CELERY_ROUTES
This is a single, or a list of routers to traverse when sending tasks. Dictionaries in this list converts to a
celery.routes.MapRouteinstance.Examples:
>>> CELERY_ROUTES = {'celery.ping': 'default', 'mytasks.add': 'cpu-bound', 'video.encode': { 'queue': 'video', 'exchange': 'media' 'routing_key': 'media.video.encode'}}
>>> CELERY_ROUTES = ('myapp.tasks.Router', {'celery.ping': 'default'})
Where myapp.tasks.Router could be:
class Router(object): def route_for_task(self, task, args=None, kwargs=None): if task == 'celery.ping': return 'default'
route_for_task may return a string or a dict. A string then means it’s a queue name in
CELERY_QUEUES, a dict means it’s a custom route.When sending tasks, the routers are consulted in order. The first router that doesn’t return None is the route to use. The message options is then merged with the found route settings, where the routers settings have priority.
Example if
apply_async()has these arguments:>>> Task.apply_async(immediate=False, exchange='video', ... routing_key='video.compress')
and a router returns:
{'immediate': True, 'exchange': 'urgent'}
the final message options will be:
>>> task.apply_async( ... immediate=True, ... exchange='urgent', ... routing_key='video.compress', ... )
(and any default message options defined in the
Taskclass)New Task handler called after the task returns:
after_return().ExceptionInfonow passed toon_retry()/on_failure()aseinfokeyword argument.
Worker: Added
CELERYD_MAX_TASKS_PER_CHILD/celery worker --maxtasksperchild.Defines the maximum number of tasks a pool worker can process before the process is terminated and replaced by a new one.
Revoked tasks now marked with state
REVOKED, and result.get() will now raiseTaskRevokedError.celery.task.control.ping()now works as expected.apply(throw=True) /
CELERY_EAGER_PROPAGATES_EXCEPTIONS: Makes eager execution re-raise task errors.New signal:
~celery.signals.worker_process_init: Sent inside the pool worker process at init.Worker:
celery worker -Qoption: Ability to specify list of queues to use, disabling other configured queues.For example, if
CELERY_QUEUESdefines four queues: image, video, data and default, the following command would make the worker only consume from the image and video queues:$ celeryd -Q image,video
Worker: New return value for the revoke control command:
Now returns:
{'ok': 'task $id revoked'}
instead of
True.Worker: Can now enable/disable events using remote control
Example usage:
>>> from celery.task.control import broadcast >>> broadcast('enable_events') >>> broadcast('disable_events')
Removed top-level tests directory. Test config now in celery.tests.config
This means running the unit tests doesn’t require any special setup. celery/tests/__init__ now configures the
CELERY_CONFIG_MODULEandCELERY_LOADERenvironment variables, so when nosetests imports that, the unit test environment is all set up.Before you run the tests you need to install the test requirements:
$ pip install -r requirements/test.txt
Running all tests:
$ nosetestsSpecifying the tests to run:
$ nosetests celery.tests.test_task
Producing HTML coverage:
$ nosetests --with-coverage3
The coverage output is then located in celery/tests/cover/index.html.
Worker: New option –version: Dump version info and exit.
celeryd-multi: Tool for shell scripts to start multiple workers.Some examples:
Advanced example with 10 workers:
Three of the workers processes the images and video queue
Two of the workers processes the data queue with loglevel DEBUG
the rest processes the default’ queue.
$ celeryd-multi start 10 -l INFO -Q:1-3 images,video -Q:4,5:data -Q default -L:4,5 DEBUG
Get commands to start 10 workers, with 3 processes each
$ celeryd-multi start 3 -c 3 celeryd -n celeryd1.myhost -c 3 celeryd -n celeryd2.myhost -c 3 celeryd -n celeryd3.myhost -c 3
Start 3 named workers
$ celeryd-multi start image video data -c 3 celeryd -n image.myhost -c 3 celeryd -n video.myhost -c 3 celeryd -n data.myhost -c 3
Specify custom hostname
$ celeryd-multi start 2 -n worker.example.com -c 3 celeryd -n celeryd1.worker.example.com -c 3 celeryd -n celeryd2.worker.example.com -c 3
Additional options are added to each
celeryd, but you can also modify the options for ranges of or single workers3 workers: Two with 3 processes, and one with 10 processes.
$ celeryd-multi start 3 -c 3 -c:1 10 celeryd -n celeryd1.myhost -c 10 celeryd -n celeryd2.myhost -c 3 celeryd -n celeryd3.myhost -c 3
Can also specify options for named workers
$ celeryd-multi start image video data -c 3 -c:image 10 celeryd -n image.myhost -c 10 celeryd -n video.myhost -c 3 celeryd -n data.myhost -c 3
Ranges and lists of workers in options is also allowed: (
-c:1-3can also be written as-c:1,2,3)$ celeryd-multi start 5 -c 3 -c:1-3 10 celeryd-multi -n celeryd1.myhost -c 10 celeryd-multi -n celeryd2.myhost -c 10 celeryd-multi -n celeryd3.myhost -c 10 celeryd-multi -n celeryd4.myhost -c 3 celeryd-multi -n celeryd5.myhost -c 3
Lists also work with named workers:
$ celeryd-multi start foo bar baz xuzzy -c 3 -c:foo,bar,baz 10 celeryd-multi -n foo.myhost -c 10 celeryd-multi -n bar.myhost -c 10 celeryd-multi -n baz.myhost -c 10 celeryd-multi -n xuzzy.myhost -c 3
The worker now calls the result backends process_cleanup method after task execution instead of before.
AMQP result backend now supports Pika.

